Smaller LLMs, Same Results. How Far Can You Compress Before Quality Breaks?
Big Power, Small Footprint. How Lean LLMs Can Deliver Peak Accuracy

Jan 28, 2026

TL;DR Smaller and compressed LLMs can deliver near-frontier accuracy for many real workloads. By measuring stability, latency, and language-specific performance—not just peak scores—you can route most tasks to lean models, reserve big models for edge cases, and significantly reduce cost without sacrificing quality.
Shipping leaner LLMs without giving up quality
At ReflektLab, we care less about model hype and more about what actually runs reliably in production. Our latest internal benchmark compares 13 LLMs across 470 tests, 4 languages (EN/FR/AR/RU) and several real product workloads (extraction, matching, message classification, data quality checks).
Instead of just asking "which model is best?", we focused on: how far can we push compression and smaller architectures before we meaningfully hurt product outcomes?
What we benchmarked
Frontier / large‑scale models:
- Meta Llama 3.3 70B Instruct (our current default)
- Qwen3 235B
- DeepSeek V3.2
- GLM‑4 32B
- Llama 4 Maverick & Scout
- Gemma 3 27B
Compressed & efficiency‑oriented models:
- Distilled: DeepSeek R1 Distill Llama 70B
- Smaller Qwen3 variants: 30B A3B Instruct, 32B
- Latency‑optimized: GLM‑4.7 Flash
- Compact Gemma: Gemma 3N E4B
Tasks mirrored our real pipelines: product & quantity extraction, product selection/grounding, message routing/classification, row‑level data checks.
The evaluation was fully automated: each test case was run 10 times per model to capture both mean performance and stability (std dev, per‑run distributions) for accuracy and latency.
Compression vs quality: what we see
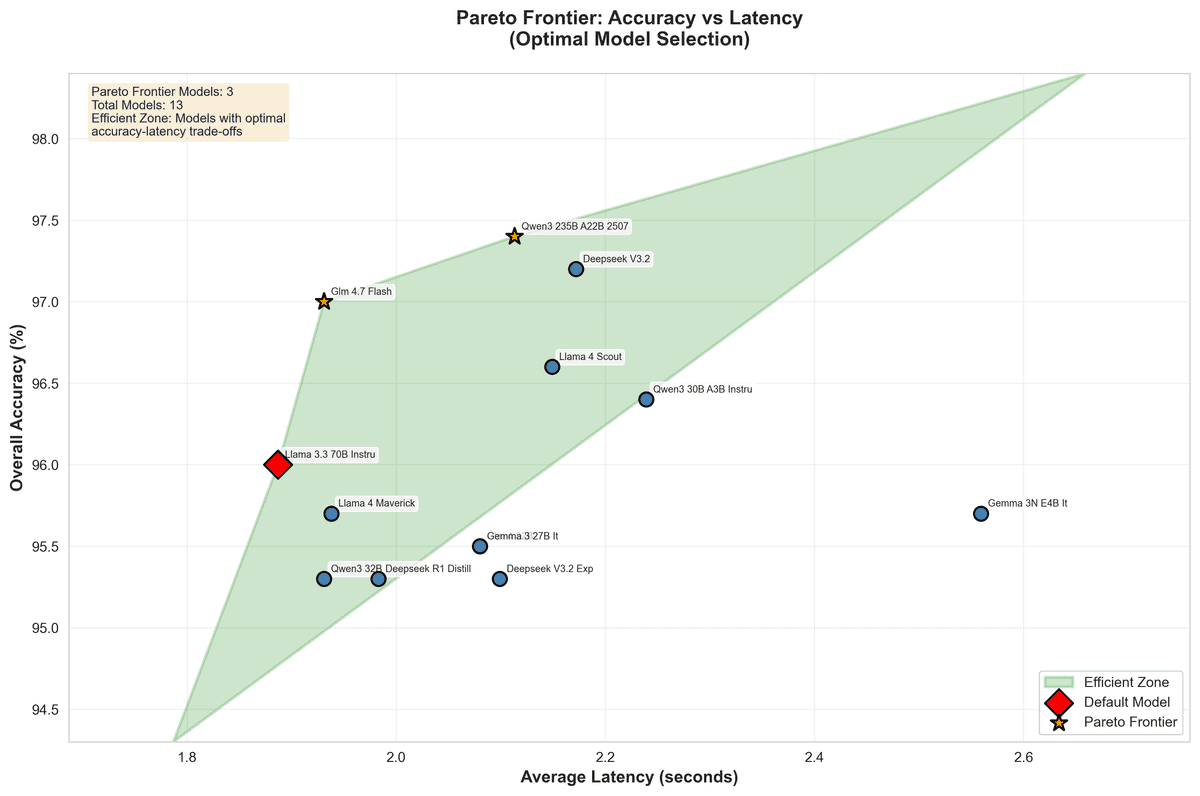
Accuracy band: most models, including compressed ones, stay in the 95–97% overall accuracy range; the top model reaches 97.4%.
Our default (Llama 3.3 70B Instruct) hits 96.0% accuracy and is also the fastest overall at 1.887s average latency, which makes it a strong "anchor" model for routing and regression checks.
Several "smaller" or distilled variants (DeepSeek V3.2, GLM‑4.7 Flash, Qwen3 30B/32B, Gemma 3N) match or beat large models on specific tasks and languages, often with lower latency and very similar stability.
On constrained tasks like product extraction, many models — including compressed ones — reach 100% accuracy, making them ideal candidates for cost‑sensitive paths.
In other words: for a significant portion of our workloads, we can route away from heavy models and still stay within a few points of peak accuracy, while cutting latency and cost.
Key Insights
Stability: production reliability matters
We ran each test 10 times to measure variance, not just averages. Our default model (Llama 3.3 70B) shows 1.21% accuracy variance across runs — more stable than the top performer (3.30% variance). In production, this difference between predictable performance and unpredictable failures. Several compressed models match or beat larger ones on stability, making them viable defaults for high‑volume workloads.
Language‑specific insights
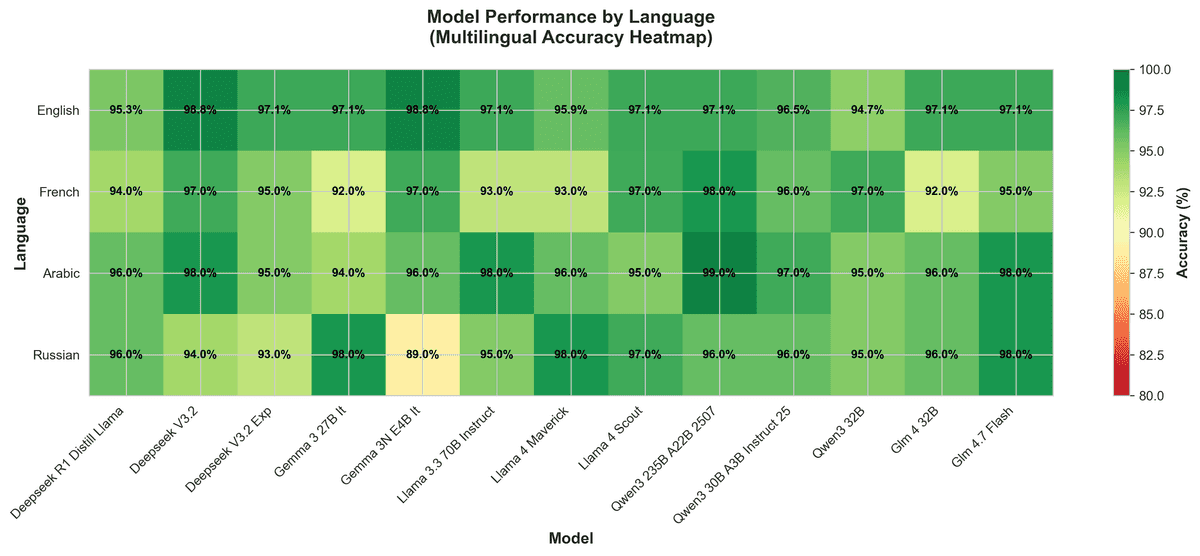
Multilingual performance varies significantly:
- Arabic: Qwen3 235B hits 99% accuracy
- Russian: GLM‑4.7 Flash (a compressed model) achieves 98% — outperforming larger models
- French: our default is fastest, but Qwen3 235B is most accurate
This language‑task matrix drives our routing decisions: different models win on different combinations.
Cost/latency trade‑offs
Latency ranges from 1.887s (fastest) to 2.559s (slowest) — a 35% difference that compounds at scale. For message classification, Gemma 3N E4B (4B params) is 20% faster than our 70B default while maintaining 100% accuracy. These trade‑offs directly impact infrastructure costs and user experience, making model selection a business decision, not just a technical one.
From benchmark to blueprint
This benchmark is not a one‑off slide deck, but a blueprint for how to design an LLM stack around real constraints. A tiered routing strategy emerges naturally: use compressed models as the default per task and language, and keep a few strong frontier models as fallbacks for high‑uncertainty or high‑risk cases.
Model swaps and compression choices are driven by continuous evaluation, not intuition, with per‑run variance and stability treated as first‑class metrics instead of only looking at "hero" numbers.
If you're exploring how to mix compression, routing and evaluation to ship faster without blowing up your GPU budget, these results show that a pragmatic, measurement‑driven approach can get you very close to state‑of‑the‑art quality with much leaner infrastructure.