Au-delà du texte : résoudre la compréhension documentaire avec les LLM de vision
Et si un seul modèle de vision multimodal pouvait comprendre n'importe quel document ? Voici ce que nous avons appris en construisant de la reconnaissance d'images en production sur des étiquettes de vin, des documents financiers et des plannings manuscrits.

Feb 24, 2026
Chaque entreprise fonctionne avec des documents — factures, fiches de paie, étiquettes produits, feuilles de présence. La plupart arrivent sous forme de photos, de PDF scannés ou d'impressions avec des annotations manuscrites. En extraire des données structurées a traditionnellement nécessité des pipelines OCR coûteux et fragiles qui cassent dès qu'une mise en page change.
Nous avons pris un autre chemin. Au lieu d'ingénier des templates pour chaque type de document, nous nous sommes demandé : et si un seul modèle de vision multimodal pouvait comprendre n'importe quel document qu'on lui soumet ?
Voici ce que nous avons appris en construisant de la reconnaissance d'images en production sur des étiquettes de vin, des documents financiers et des plannings manuscrits.
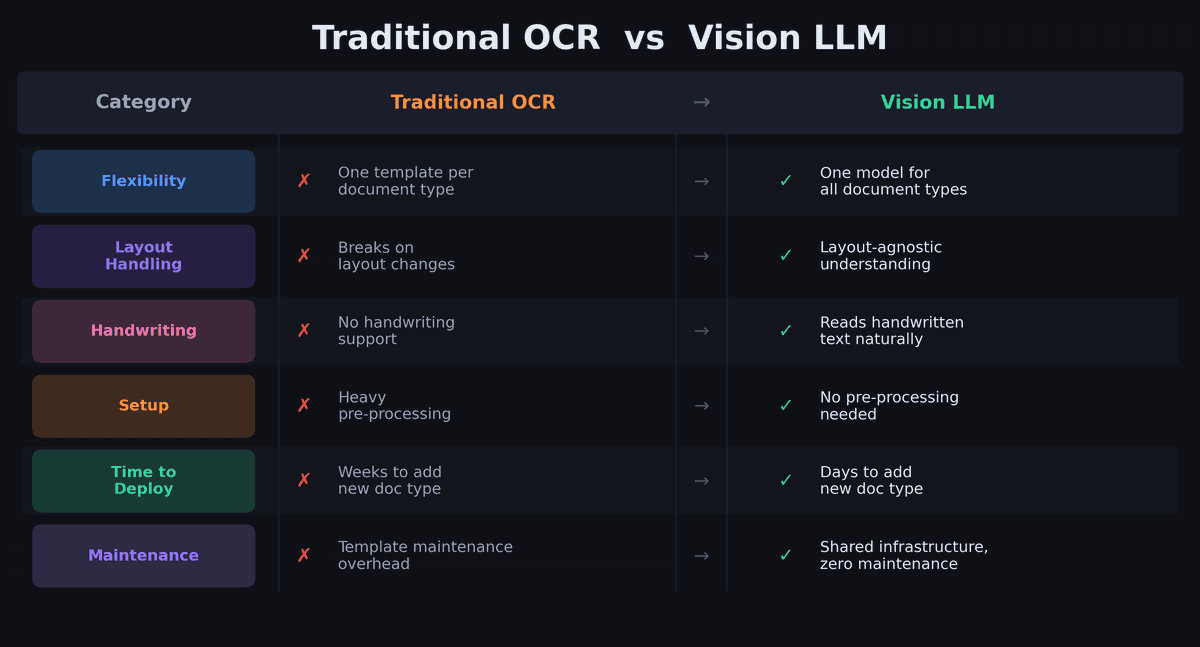
Défi #1 : Chaque document est différent
Les étiquettes de vin existent en milliers de designs. Les fiches de paie françaises varient énormément selon les éditeurs de paie. Les plannings de crèche mélangent tableaux imprimés et annotations manuscrites. Une approche OCR traditionnelle nécessiterait un template séparé pour chaque mise en page — et une maintenance constante à mesure que les formats changent.
Notre approche : Nous définissons un schéma structuré pour chaque type de document en utilisant des signatures DSPy — en disant essentiellement au modèle de vision quoi extraire, pas où le trouver. Le modèle comprend la mise en page et le contexte par lui-même. Un prompt pour étiquette de vin spécifie "extraire domaine, appellation, millésime, région" sans avoir besoin de savoir si le millésime est imprimé en haut, en bas ou sur une collerette.
Cela signifie qu'ajouter un nouveau type de document revient à écrire un nouveau prompt et un schéma de sortie — pas à construire un nouveau pipeline.
Défi #2 : Des entrées réelles désordonnées
Les documents en production sont rarement propres. Nous traitons régulièrement :
- Des bouteilles de vin photographiées en angle, en basse lumière, avec des reflets sur le verre
- Des fiches de paie scannées de travers avec des tampons, signatures et notes manuscrites superposés
- Des feuilles de présence dont la moitié des entrées sont des corrections manuscrites sur du texte imprimé
- Des PDF multi-pages mélangeant tableaux, blocs de texte et images
L'OCR classique bloque sur ces cas. Les LLM de vision les gèrent naturellement — ils comprennent le contexte visuel comme un lecteur humain. Un "X 17h45" manuscrit à côté du nom d'un enfant sur un planning est tout aussi lisible pour le modèle qu'une cellule de tableau proprement imprimée.
Pour les PDF spécifiquement, nous les traitons nativement plutôt que de les convertir en images d'abord. Cela préserve la fidélité du texte et la structure des tableaux qui seraient autrement perdues lors de la rastérisation.
Défi #3 : Fiabilité des sorties structurées
Les modèles de vision sont excellents pour comprendre les documents mais inconstants pour formater leurs réponses. En production, nous avons constaté que 5 à 10% des réponses arrivent avec des problèmes :
- Du JSON enveloppé dans des blocs de code markdown
- Des retours à la ligne littéraux dans les valeurs de chaînes
- Un préambule conversationnel avant les données réelles
- Des champs hallucinés occasionnels
Notre solution : Un pipeline de récupération JSON multi-étapes qui gère chaque mode d'échec en séquence :
Parse JSON direct
↓ (échoue ?)
Supprimer les fences markdown + réessayer
↓ (échoue ?)
Échapper les retours à la ligne + réessayer
↓ (échoue ?)
Extraire les accolades { } les plus externes + réessayer
Cela nous fait passer d'un taux de succès de ~90% au premier passage à 99%+ après récupération. La différence entre "ça marche en démo" et "ça marche en production".
Défi #4 : Performance en production à l'échelle
L'inférence des modèles de vision est intrinsèquement plus lente que les appels texte seul — typiquement 3 à 10 secondes par document. Lors du traitement de lots de centaines de documents, un traitement séquentiel naïf est inacceptable.
Notre approche :
- Architecture async-first — chaque appel vision s'exécute hors de la boucle d'événements principale avec des timeouts stricts de 60 secondes
- Traitement par lots concurrent — un parallélisme contrôlé par sémaphore empêche la saturation des limites de taux API tout en maximisant le débit
- Retries avec backoff exponentiel — les échecs transitoires sont gérés automatiquement sans intervention manuelle
- Post-traitement parallèle — pour les étiquettes de vin, la correspondance en base de données pour plusieurs vins détectés s'exécute en parallèle après l'extraction
Le résultat : un lot de 100 documents se traite en minutes, pas en heures.
L'avantage architectural : un pattern, de nombreux types de documents
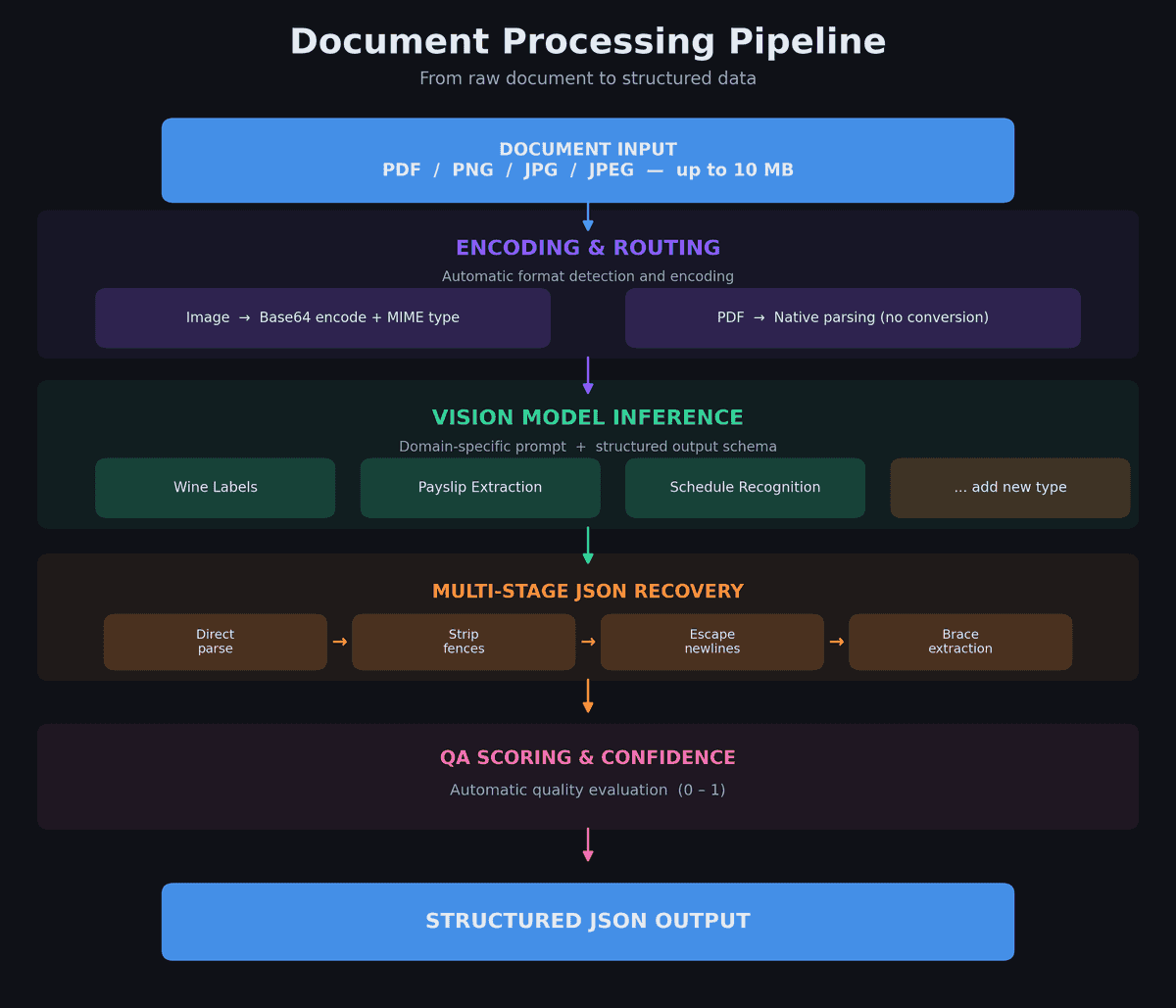
L'insight clé derrière notre système est que toute extraction basée sur la vision suit le même pattern :
Entrée (image/PDF) → Encodage → Prompt domaine + schéma → Modèle de vision → Récupération JSON → Score QA → Sortie structurée
La seule chose qui change entre les types de documents est le prompt et le schéma de sortie. L'encodage, le routage de modèle, la récupération JSON, l'évaluation QA, l'exécution async et la gestion d'erreurs sont tous de l'infrastructure partagée.
Cela signifie que passer de "nous devons lire un nouveau type de document" à "c'est en production" prend des jours, pas des mois. Le gros du travail — parsing robuste, scoring de confiance, traitement par lots, gestion des timeouts — est déjà résolu.
En résumé
L'OCR traditionnel est un jeu de templates et de cas limites. Les LLM de vision inversent l'approche : au lieu de dire au système comment lire chaque document, vous lui dites quoi extraire et laissez le modèle se débrouiller pour le reste.
Les défis sont réels — formatage de sortie inconstant, qualité d'entrée variable, et performance à l'échelle. Mais chacun a une solution systématique qui se généralise à travers les types de documents.
Si vous maintenez des pipelines OCR séparés pour différents formats de documents, ou si vous traitez manuellement des documents qui arrivent sous forme de photos et de scans, l'approche LLM multimodal mérite d'être évaluée. Le coût par appel baisse rapidement, la précision sur des entrées réelles désordonnées est déjà de qualité production, et le temps de déploiement pour de nouveaux types de documents est dramatiquement plus court que de construire encore un autre pipeline basé sur des templates.
Vous voulez voir comment nous optimisons les coûts LLM en production ? Consultez nos benchmarks de coût-efficacité et nos résultats de comparaison de modèles.