Votre courbe de vélocité vous ment
Linear suppose qu'une heure-développeur livre un point. Avec Claude Code, elle en livre quatre à sept. Voici comment nous avons reconstruit le suivi de vélocité pour apprendre le vrai multiplicateur de chacun à partir de son historique.

Jun 15, 2026
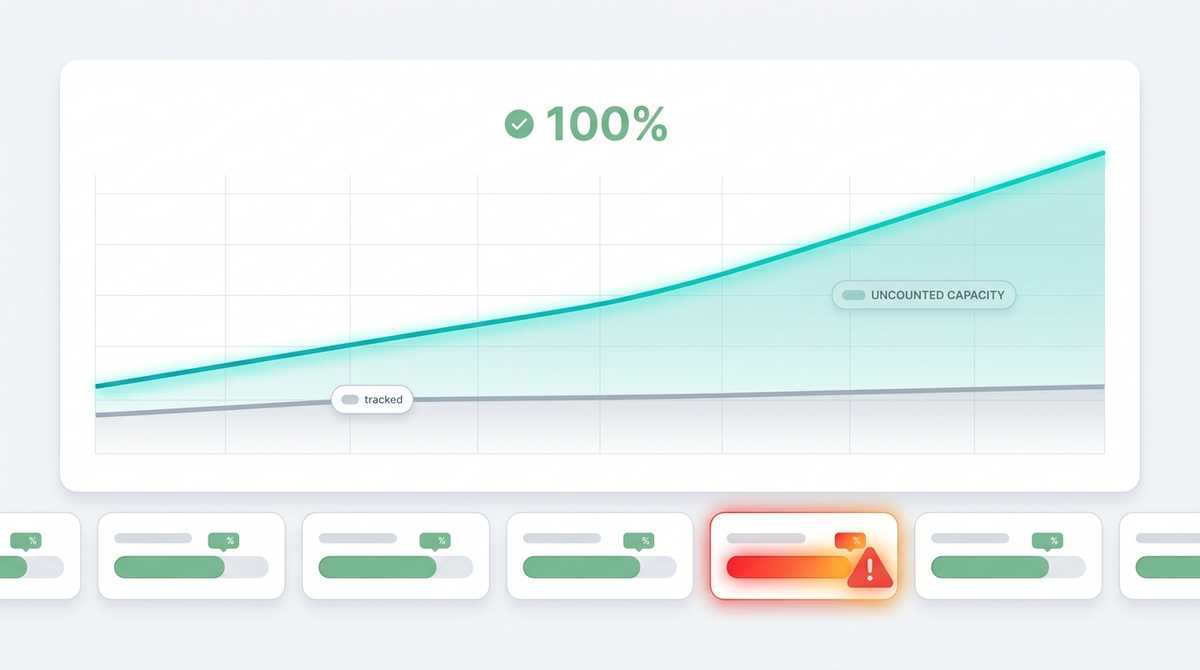
Tous les outils de suivi de projet font silencieusement la même hypothèse : un développeur, pendant une heure calendaire, livre un point de travail. Les story points, les courbes de vélocité, les burndown — tout repose sur cette conversion. Elle a tenu pendant une décennie.
Puis nous avons mis Claude Code et les git worktrees entre les mains de toute l'équipe, et la conversion a cédé.
Un développeur senior qui pilote trois ou quatre agents en parallèle livre désormais quatre à sept points dans le temps que la courbe compte encore comme « une heure d'une personne ». La vélocité n'a pas augmenté de 10 %. Pour certains, elle a bondi de 600 % — et la courbe n'avait aucun moyen de le voir. Elle continuait de mesurer des points bruts contre du temps calendaire, continuait de sous-estimer notre vraie capacité, et continuait de nous dire que personne n'était surchargé alors que certains l'étaient manifestement.
Voici comment nous avons corrigé cela : non pas en gonflant les estimations, mais en apprenant le multiplicateur effectif de chaque personne à partir de son propre historique, et en l'appliquant automatiquement.
La mauvaise solution, séduisante
Le réflexe évident, c'est de pré-multiplier les estimations. Si un développeur est « 4× plus rapide », on dimensionne ses tickets au quart des heures.
Nous l'avons rejeté fermement, pour trois raisons :
- Cela détruit l'estimation comme langage commun. Un ticket de 5 points doit signifier la même chose quel que soit celui qui le prend : environ cinq heures de travail concentré pour un développeur standard. Dès que vous incorporez la vitesse d'une personne dans le chiffre, deux personnes ne parlent plus du même ticket.
- Le multiplicateur n'est pas un seul chiffre. Il diffère selon la personne, il diffère entre les petits et les gros tickets, et il dérive à chaque amélioration de l'outillage. Tout ce que vous codez à la main est faux en moins d'un mois.
- Cela masque le signal qui vous intéresse vraiment. La question intéressante n'est pas « à quelle vitesse va ce ticket » — c'est « cette personne accélère-t-elle, ralentit-elle, est-elle surchargée ou bloquée ? ». Les estimations pré-multipliées effacent exactement cela.
Nous avons donc gardé l'estimation honnête — un point égale une heure de travail concentré, au rythme d'un développeur standard, jamais pré-multipliée pour le parallélisme — et déplacé toute la variation par personne dans une couche séparée et apprise.
Apprendre le multiplicateur depuis l'historique
L'idée centrale est simple : pour chaque ticket qu'une personne a clôturé, nous connaissons déjà deux choses — ce que nous avions estimé, et le temps que cela a réellement pris. Le rapport entre les deux est son multiplicateur sur ce ticket.
multiplicateur_du_ticket = (points_estimes / 8) / jours_de_cycle
Une personne qui clôture un ticket de 8 points en une journée de travail tourne à 1×. En deux heures, elle tourne à ~4×. Faites cela sur tout l'historique des tickets clôturés d'une personne et vous obtenez une distribution, pas une supposition.
Nous ne nous contentons pas d'en faire la moyenne, car une moyenne naïve ment dans les deux sens. L'agrégation est :
- Pondérée par la récence avec une demi-vie de 30 jours, pour que le rythme du trimestre dernier n'écrase pas celui de ce mois-ci.
- Une médiane pondérée, pas une moyenne, pour qu'un ticket resté trois semaines en revue ne plombe pas tout le chiffre.
- Accompagnée d'un écart interquartile, pour montrer la confiance dans le chiffre, et pas seulement l'estimation ponctuelle.
- Séparée par taille de ticket — les petits tickets (1 à 3 points) et les gros (5+) ont des multiplicateurs distincts, car enchaîner des petites tâches n'a rien à voir avec creuser une grosse fonctionnalité.
Les personnes ayant trop peu de tickets clôturés pour être significatives retombent sur une valeur par défaut prudente, plutôt que de produire un chiffre confiant à partir de trois points de données. L'ensemble s'auto-calibre : personne n'édite un fichier de config quand quelqu'un devient plus rapide. C'est l'historique qui le fait.
Deux horloges, deux multiplicateurs
Voici une subtilité qui nous a pris du temps à bien régler. Il y a deux questions différentes cachées dans « combien de temps cela a pris », et elles exigent deux horloges différentes.
- Le temps de cycle actif — uniquement les périodes où le ticket était réellement En cours, week-ends exclus. Cela mesure la vitesse d'ingénierie pure. C'est le chiffre qu'il vous faut pour une conversation sur la vélocité d'équipe.
- Le temps de cycle calendaire — du début à la clôture en temps réel, y compris chaque heure passée à attendre dans une file de revue. C'est le chiffre honnête pour le coût.
L'écart entre les deux est énorme pour certains flux de travail. La vitesse de codage pure d'un développeur peut être de 5×, tandis que son temps calendaire jusqu'à la clôture est bien plus lent parce que ses PR attendent la revue. Si vous utilisiez le chiffre actif pour le coût, vous diviseriez son coût par deux sur le papier — mais vous avez quand même payé chaque heure pendant laquelle le travail patientait dans la file. Donc la vitesse d'ingénierie se lit sur l'horloge active, et l'argent se lit sur l'horloge calendaire. Mêmes données, deux valorisations, aucune fiction dans l'une comme dans l'autre.
Ce que l'on construit par-dessus
Une fois que chaque personne dispose d'un multiplicateur fiable, le reste du tableau de bord en découle :
capacite = heures_contrat x multiplicateur_effectif // points effectifs par semaine
charge = engagement_ouvert / capacite // a quel point le pipeline est plein
La capacité cesse d'être un « 40 heures » plat et devient des points effectifs par semaine — ce que cette personne précise, avec son outillage réel, peut livrer. La charge est l'engagement ouvert rapporté à cette capacité, ce qui nous permet enfin de signaler qui est réellement surchargé (et qui a de la marge) sans deviner.
Et le sens de « 100 % » change d'une manière que nous estimons juste. Cela ne signifie plus « vous avez atteint un standard abstrait d'un point par heure ». Cela signifie « vous avez tenu votre propre rythme historique cette semaine ». Toute une équipe peut afficher 100 % tout en livrant à des rythmes absolus très différents — et c'est très bien ainsi. Le rôle du tableau de bord n'est pas de classer les gens les uns contre les autres. C'est de signaler le changement : la personne qui filait et qui est maintenant bloquée, la file qui s'engorge, le projet qui consomme discrètement plus qu'il ne clôture.
La semaine de 40 heures est aussi une fiction
Encore un problème d'honnêteté. Le calcul de capacité ci-dessus supposait toujours que chacun fait une semaine contractuelle plate sur une enveloppe bien rangée du lundi au vendredi. C'est faux pour quiconque travaille le matin, le soir et le week-end — et lire ses rattrapages nocturnes comme s'il s'agissait d'un 9 h-17 normal déforme silencieusement ce qu'il a réellement investi.
Nous apprenons donc aussi l'empreinte réelle, à partir de l'activité horodatée — heures de commit, transitions de tickets, créneaux d'agenda. Par jour actif, nous prenons l'amplitude de la fenêtre de travail (de la première activité à la dernière), bornée dans une plage raisonnable, et nous la mélangeons vers le chiffre contractuel selon la quantité de signal réellement disponible cette semaine-là. Une semaine peu fournie reste ancrée au contrat pour ne pas fausser les chiffres ; une semaine réellement large apparaît comme large.
C'est délibérément un indicateur indirect, pas une feuille de temps — l'historique des commits ne voit pas le temps de pure réflexion, et nous ne prétendons jamais le contraire. Mais cela transforme « êtes-vous dans le rythme ? » en la décomposition honnête qu'elle aurait toujours dû être : les heures réellement investies, multipliées par la production par heure. Deux cadrans distincts, aucun ne se cachant derrière l'autre.
Pourquoi cela compte au-delà de notre équipe
Les détails sont les nôtres, mais la leçon se généralise à quiconque met des outils d'IA entre les mains de ses ingénieurs :
Vos métriques de productivité actuelles ont été calibrées pour un monde qui n'existe plus. Elles supposent une conversion fixe entre le temps humain et le travail livré, et c'est précisément cette conversion que l'outillage IA a fait voler en éclats — de façon inégale, par personne, et toujours en mouvement.
Vous avez deux options. Faire comme si rien n'avait changé et regarder vos courbes se détacher lentement de la réalité. Ou cesser de coder la conversion en dur et commencer à la mesurer — par personne, à partir de l'historique réel, pondérée par la récence, recalculée chaque jour. Nous avons choisi la seconde. Les estimations sont restées honnêtes, la courbe de vélocité s'est remise à dire la vérité, et pour la première fois nous pouvions voir qui avait réellement de la marge pour en prendre plus et qui était sur le point de couler.
L'heure n'a pas cessé d'être utile. Elle a juste cessé d'être une constante. Dès que vous laissez le multiplicateur flotter et que vous l'apprenez à partir des données, tout ce qui repose dessus — capacité, charge, coût, planning — se remet discrètement à fonctionner.