Construire un Contexte Plus Intelligent : Les Stratégies de Recherche Qui Rendent l'IA Vraiment Utile
Aucune stratégie de recherche seule ne suffit. Combiner recherche sémantique, structurée et floue masque les faiblesses de chaque méthode tout en cumulant leurs forces.

Mar 12, 2026
Les modèles d'IA sont puissants, mais ils ne valent que par le contexte qu'on leur fournit. Demandez à un modèle de catégoriser une transaction ou de matcher un produit sans exemples de référence, et vous obtiendrez des résultats confiants mais faux. Donnez-lui les 10 à 15 bons exemples tirés de vos propres données, et la précision passe de "niveau démo" à "niveau production".
La difficulté n'est pas l'appel à l'IA — c'est de trouver le bon contexte à lui fournir.
Nous exploitons plusieurs pipelines en production — matching de produits, catégorisation de transactions, mapping d'inventaire — chacun tirant son contexte de tableurs et de services externes. Au fil du temps, un schéma clair a émergé : aucune stratégie de recherche seule ne suffit, mais les combiner masque les faiblesses de chacune tout en cumulant leurs forces.
Cet article détaille les trois stratégies de recherche que nous utilisons, où chacune échoue, et pourquoi les superposer fonctionne.
Le Schéma : Recherche → Fusion → Raisonnement → Validation
Chaque pipeline d'IA enrichi par le contexte suit la même forme :
Entrée → Recherche parallèle (stratégies multiples) → Dédoublonnage & classement → Raisonnement IA avec contexte → Validation de la sortie
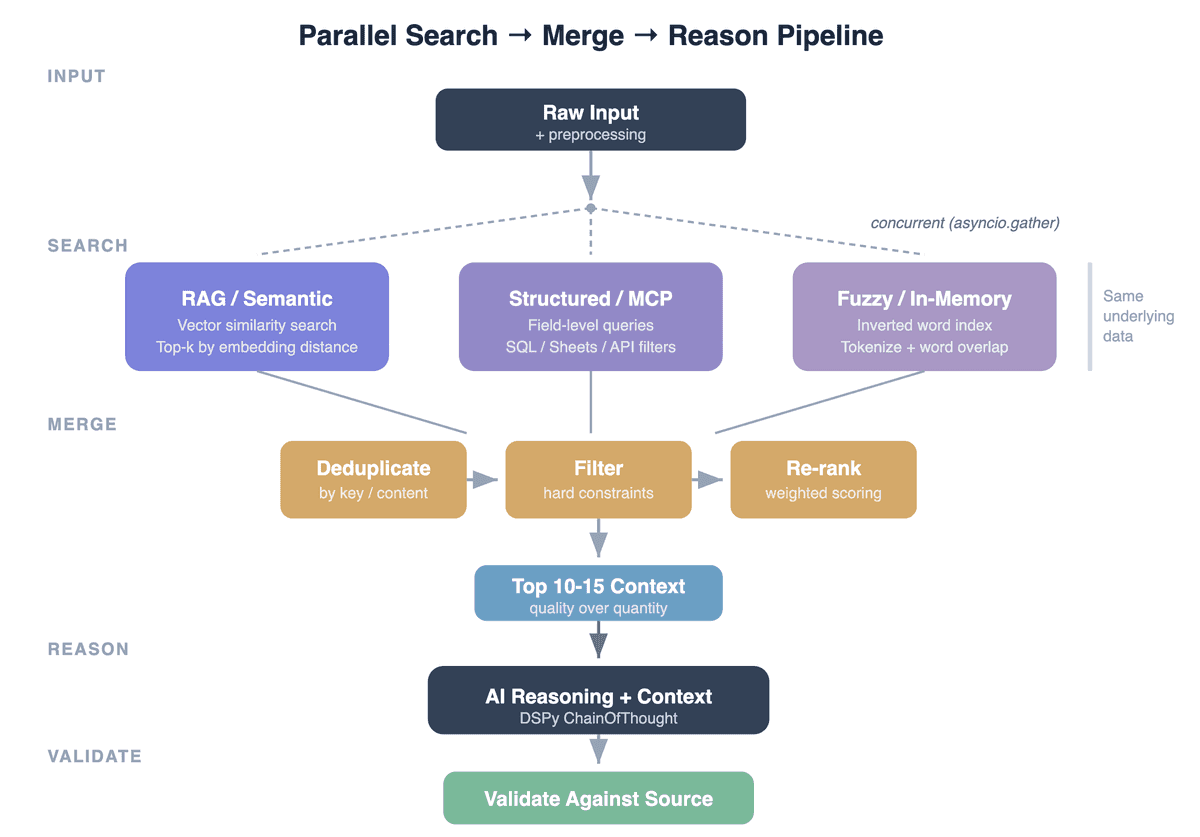
La partie intéressante est la couche de recherche. Chaque stratégie a un mode d'échec fondamentalement différent — et c'est exactement pour cela que les combiner fonctionne.
RAG (Génération Augmentée par la Recherche) Recherche Sémantique : Comprend le Sens, Perd en Précision
Comment ça marche : Vos données de référence sont découpées en texte, transformées en vecteurs, et stockées dans une base vectorielle. Au moment de la requête, l'entrée est vectorisée et les voisins les plus proches sont retournés par similarité cosinus.
Où ça excelle :
- Entrées paraphrasées ou reformulées. "VIR SEPA LEASYS FRANCE SAS LOYER" et "VIREMENT LEASYS — LEASE MENSUEL" sont distants en espace lexical mais proches en espace d'embedding.
- Requêtes plus longues et descriptives où le modèle d'embedding capture bien le sens global.
- Découverte — trouver des enregistrements pertinents que vous n'auriez pas pensé à chercher par mot-clé.
Où ça échoue :
- Identifiants exacts. Les embeddings brouillent la différence entre "61350000" et "61360000" — ce sont tous deux des codes à 8 chiffres, sémantiquement identiques pour le modèle. Si votre tâche dépend du matching exact de codes, le RAG retournera parfois le mauvais.
- Noms structurellement similaires mais sémantiquement différents. "St Emilion" et "St Estephe" partagent le même préfixe et la même forme — les embeddings les scorent souvent plus proches l'un de l'autre que "St Emilion" et "Saint-Émilion", qui sont en réalité le même endroit. Le modèle voit la similarité de surface, pas la connaissance du domaine. C'est un piège courant : les noms courts avec une structure partagée trompent la recherche vectorielle.
- Matching de champs structurés. Quand vous avez besoin de "Domaine = X ET Région = Y", la similarité sémantique ne respecte pas les frontières de champs. Un enregistrement avec le bon domaine mais la mauvaise région peut scorer plus haut que la correspondance exacte.
- Entrées courtes et cryptiques. Les codes bancaires, SKU ou noms de produits abrégés ne s'embedent pas bien — il n'y a pas assez de signal sémantique.
Adéquation aux sources de données :
- Fonctionne bien sur toute donnée riche en texte : lignes de tableur sérialisées en chaînes, enregistrements de base de données aplatis en texte, fragments de documents, entrées de log.
- Également applicable à PostgreSQL full-text, Elasticsearch, ou une base vectorielle dédiée — le schéma est le même quelle que soit la source des données brutes.
MCP (Model Context Protocol) / Recherche Structurée : Recherches Précises, Fragile aux Variations
Comment ça marche : Une requête structurée contre votre source de données — Google Sheets via des outils MCP, une requête SQL contre une base de données, un appel API vers un service de recherche. La requête est analysée à partir de l'entrée (extraction des noms d'entités, filtrage par type) et exécutée comme une recherche directe.
Où ça excelle :
- Matching exact de champs. "Donne-moi tous les produits où Domaine = 'Domaine Faiveley'" retourne exactement cela — pas d'approximation.
- Recherche filtrée. Combiner plusieurs contraintes (type + région + nom) réduit les résultats aux enregistrements précisément pertinents.
- Résultats déterministes. La même requête retourne toujours les mêmes résultats. Pas de dérive d'embedding, pas de sensibilité à la version du modèle.
Où ça échoue :
- Fautes de frappe et abréviations. Chercher "Chateau Latour" quand l'enregistrement dit "Château Latour" — décalage d'accent, zéro résultat. Chercher "Dom. Faiveley" quand l'enregistrement dit "Domaine Faiveley" — pas de correspondance.
- Reformulations. L'utilisateur écrit "vin rouge de Bourgogne" ; le champ de la base dit "Bourgogne". La recherche structurée n'a aucun concept de synonymie.
- Couplage au schéma. Chaque nouvelle source de données nécessite une logique de requête adaptée à son schéma. Passer de Google Sheets à PostgreSQL et le code de recherche change, même si le schéma est identique.
Adéquation aux sources de données :
- Naturel pour les bases de données (clauses SQL WHERE), Google Sheets (filtrage par colonnes via MCP), API REST avec paramètres de filtre.
- Peut être abstrait derrière des outils MCP — le pipeline LLM n'a pas besoin de savoir si le backend est Sheets, Postgres ou Salesforce ; le serveur MCP gère la traduction.
Recherche Floue / En Mémoire : Attrape les Correspondances Partielles, Bruitée à Grande Échelle
Comment ça marche : Construire un index inversé de mots à partir de vos données de référence au démarrage. Au moment de la requête, tokeniser l'entrée, supprimer les mots vides, et scorer les enregistrements par chevauchement de mots. Optionnellement, ajouter du matching par distance d'édition pour la tolérance aux fautes de frappe.
Où ça excelle :
- Correspondances partielles entre champs. L'entrée "Bourgogne Pinot Noir Faiveley 2020" correspond à un enregistrement où "Bourgogne" est dans le champ région, "Pinot Noir" dans le champ cépage, et "Faiveley" dans le champ domaine. Ni le RAG (qui embedde la chaîne entière) ni la recherche structurée (qui interroge un champ à la fois) ne gèrent bien cela.
- Descriptions composées. Les entrées réelles contiennent souvent des informations provenant de multiples champs de schéma mélangés ensemble. Le chevauchement au niveau des mots comble naturellement cet écart.
- Zéro infrastructure. Pas de base vectorielle, pas de service de recherche — juste un dictionnaire en mémoire construit au démarrage. Souvent une latence en millisecondes pour des recherches indexées sélectives.
Où ça échoue :
- Échelle. Fonctionne très bien pour des milliers d'enregistrements. À des millions, l'index inversé devient volumineux et le scoring coûteux. À ce stade, il faut un vrai moteur de recherche.
- Fossés sémantiques. "Paiement de leasing" et "LOYER MENSUEL" ne partagent aucun mot. La recherche floue ne les connectera pas.
- Bruit à faible chevauchement. Un seul mot correspondant peut faire remonter des enregistrements non pertinents. Sans seuil minimum de chevauchement, les résultats se dégradent rapidement.
Adéquation aux sources de données :
- Idéal pour les jeux de données assez petits pour tenir en mémoire (jusqu'à quelques centaines de milliers d'enregistrements).
- Fonctionne de manière identique quelle que soit la source — chargement depuis un tableur, un dump de base de données, un CSV ou une réponse API. L'index est construit dans le processus.
Pourquoi la Superposition Fonctionne : Les Modes d'Échec ne Sont pas Corrélés
L'insight clé : ces trois stratégies échouent sur des entrées différentes.

Quand vous exécutez les trois en parallèle et fusionnez les résultats, la stratégie gagnante est presque toujours présente pour n'importe quelle entrée. La couche de fusion et de classement n'a qu'à la faire remonter.
Le coût de la superposition est faible :
- Chaque recherche supplémentaire ajoute des millisecondes (elles s'exécutent simultanément).
- Le dédoublonnage supprime les résultats redondants avant qu'ils n'atteignent le modèle d'IA.
- Le modèle ne se soucie pas de quelle stratégie a trouvé le contexte — il a juste besoin des bons exemples.
La Couche de Fusion : Dédoublonnage, Filtrage, Re-Classement
Exécuter trois recherches produit des résultats redondants, parfois contradictoires. La couche de fusion est critique :
Dédoublonnage : Le même enregistrement trouvé par plusieurs stratégies → en garder un. Nous dédoublonnons par contenu normalisé (minuscules, espaces condensés). Pour les sources adossées à une base de données, le dédoublonnage par clé primaire est encore plus fiable.
Filtrage : Supprimer les résultats qui violent les contraintes dures. Si l'entrée spécifie "Type = Vin Rouge", éliminer tout résultat Vin Blanc quel que soit le score de recherche. C'est là que vit la logique métier.
Re-classement : Scorer les résultats restants par pertinence par rapport à l'entrée originale. Nous utilisons un chevauchement de mots pondéré (poids différents par champ — les noms d'entités comptent plus que les catégories). Ce re-classement corrige les différences de sémantique de scoring entre les backends de recherche.
Plafond de contexte : Limiter le contexte final à 10–15 entrées. Nous avons testé un contexte non plafonné et constaté qu'au-delà d'environ 15 exemples, l'IA commence à "moyenner" tous les exemples plutôt qu'à identifier la meilleure correspondance. Moins d'exemples, plus pertinents, surpassent systématiquement beaucoup d'exemples médiocres.
Pré-Traitement : La Qualité du Contexte Commence Avant la Recherche
La qualité de la recherche dépend du nettoyage de l'entrée. Avant toute recherche :
- Développer les abréviations de manière déterministe (raccourcis spécifiques au domaine → forme complète). Cela corrige l'angle mort du RAG sur les entrées cryptiques.
- Normaliser l'encodage (accents, unicode, casse). Cela corrige la fragilité de la recherche structurée aux variations.
- Supprimer les tokens de bruit (codes de taille, préfixes de format, texte standard). Cela améliore la précision de la recherche floue en réduisant les faux chevauchements de mots.
- Retours anticipés pour les entrées trivialement résolvables (schémas connus qui n'ont pas besoin de raisonnement LLM).
Le pré-traitement est invisible pour l'IA mais fait souvent une plus grande différence de précision que de changer de modèle.
Validation Post-IA : Faire Confiance mais Vérifier
Les sorties d'IA enrichies par le contexte sont meilleures, mais pas parfaites. Schémas de validation :
- Validation de catégorie : Vérifier les catégories prédites par rapport à l'ensemble valide connu. Signaler ou rejeter les inconnues.
- Matching progressif de clés : Essayer la correspondance exacte avec les données de référence, puis relâcher progressivement les contraintes (supprimer les champs optionnels) jusqu'à trouver une correspondance ou que la confiance tombe sous le seuil.
- Vérification de cohérence sortie-entrée : Vérifier que les termes distinctifs de l'entrée apparaissent dans la sortie. Si le modèle a halluciné une entité différente, se replier sur le résultat de recherche le mieux classé.
Un Schéma Différent : La Recherche Agentique pour l'Usage Interactif
Le pipeline de recherche parallèle décrit ci-dessus est conçu pour le traitement par lots — des centaines ou milliers d'éléments traités de manière cohérente, sans intervention humaine. La même entrée déclenche toujours les mêmes stratégies de recherche, la même logique de fusion, la même validation. C'est déterministe, reproductible et optimisé pour le débit.
Mais tous les cas d'usage ne sont pas par lots. Notre assistant CRM adopte une approche fondamentalement différente, conçue pour des requêtes interactives, une à la fois, d'un utilisateur.
Le pipeline CRM traite des requêtes en langage naturel — "comment va Marcelo ?" ou "crée un contact chez TechCorp" — via un agent ReAct (Raisonnement + Action). Au lieu de pré-rassembler le contexte et de raisonner une fois, l'IA décide quoi chercher, de manière itérative, en appelant des outils MCP contre un CRM adossé à PostgreSQL :
Requête → Le LLM choisit un outil → MCP exécute la requête → Le LLM lit le résultat → Le LLM agit ou répond (jusqu'à 5 itérations)
Le serveur MCP expose plusieurs outils différents (filtres SQL par nom, statut, cycle de vie, priorité), plus des opérations d'écriture avec support de simulation. Les listes plus petites comme les lots et les tags utilisent du matching de sous-chaînes en mémoire.
Pourquoi cela fonctionne pour l'usage interactif mais pas pour le traitement par lots :
- Un utilisateur, une question à la fois. L'IA peut passer plusieurs itérations à affiner sa recherche — si une requête ne retourne rien, l'agent ReAct essaie différents paramètres ou une requête plus large. Abordable pour une seule requête ; prohibitivement coûteux à grande échelle.
- Les données CRM sont bien structurées. Les contacts ont des noms, des entreprises, des statuts, des étapes. Les utilisateurs cherchent par ces champs — pas par similarité sémantique. La recherche structurée seule couvre l'espace des requêtes.
- La tolérance à la latence est plus élevée. Un utilisateur qui attend 2–3 secondes pour une réponse CRM, c'est acceptable. Traiter 500 lignes d'inventaire à 2–3 secondes chacune avec plusieurs appels LLM par ligne, non.
L'heuristique : utilisez la recherche agentique pour les requêtes interactives face à l'utilisateur où l'IA peut itérer et le modèle de données est propre. Utilisez le contexte pré-rassemblé en parallèle pour le traitement par lots — où vous avez besoin de cohérence (même recherche pour chaque élément), de débit (recherches simultanées, un appel IA par élément) et de débuggabilité (les diagnostics de recherche vous disent exactement quelle stratégie a contribué quoi).
Application Au-Delà des Tableurs : Bases de Données, API et Plus
Mais le schéma est agnostique à la source de données :
Bases de données relationnelles (PostgreSQL, MySQL) :
- Recherche structurée → Requêtes SQL avec clauses WHERE, paramétrées par les champs analysés de l'entrée. Les index sur les colonnes fréquemment interrogées rendent souvent cela sub-milliseconde sous charge légère.
- RAG → Embedder les lignes de table en texte (concaténer les colonnes pertinentes), indexer dans pgvector ou une base vectorielle adjacente. Même recherche sémantique, adossée à votre base existante.
- Flou → Extension
pg_trgmpour le matching flou basé sur les trigrammes, ouILIKEavec wildcards. Alternativement, charger un ensemble de travail en mémoire au démarrage pour le scoring par chevauchement de mots.
Bases documentaires (MongoDB, Elasticsearch) :
- Recherche structurée → Requêtes term/match Elasticsearch. Recherche MongoDB
$textou requêtes regex. - RAG → Champs de vecteurs denses Elasticsearch avec recherche kNN, ou MongoDB Atlas Vector Search. Les deux supportent nativement les requêtes hybrides mot-clé+vecteur.
- Flou → Paramètre
fuzzinessd'Elasticsearch sur les requêtes match. MongoDB$regexpour les motifs simples.
API externes (CRM, ERP, SaaS) :
- Recherche structurée → Paramètres de filtre API. La plupart des API SaaS supportent la recherche par champ spécifique.
- RAG → Synchronisation périodique : extraire les enregistrements, embedder, indexer. Chercher dans l'index vectoriel local, retourner les enregistrements correspondants avec leurs identifiants API.
- Flou → Dépend des capacités de l'API. Beaucoup offrent une recherche floue intégrée ; sinon, synchroniser et construire un index local.
La couche d'abstraction (MCP dans notre cas) rend cela pratique. Le pipeline IA appelle "chercher des enregistrements similaires" — le serveur MCP traduit cela en requête backend appropriée. Remplacez Google Sheets par PostgreSQL, et seule l'implémentation de l'outil MCP change.
Ce Que Nous Avons Appris
- Superposer les stratégies bat l'optimisation d'une seule. Chaque méthode de recherche a des angles morts structurels. Exécuter les trois et fusionner les résultats est plus simple et plus robuste que de perfectionner une seule approche.
- Qualité du contexte > quantité de contexte. 15 exemples bien choisis battent 50 médiocres. Le dédoublonnage, le filtrage et le re-classement comptent plus que le volume de récupération.
- Le pré-traitement fait la moitié du travail. L'expansion des abréviations et la normalisation avant la recherche font souvent une plus grande différence de précision que de changer de modèle.
- Choisissez votre schéma selon la charge de travail. Le traitement par lots nécessite une recherche parallèle déterministe. Les cas d'usage interactifs peuvent se permettre l'itération agentique. Ne forcez pas un schéma sur les deux.
L'Essentiel
Le modèle d'IA est la partie facile. L'infrastructure de recherche qui l'alimente détermine si votre système fonctionne en production. Recherche sémantique, recherche structurée et matching flou couvrent chacun des modes d'échec différents. Superposez-les, dédoublonnez, classez — et l'IA obtient un contexte suffisamment bon pour raisonner correctement.
Si votre pipeline IA sous-performe, regardez d'abord le contexte. Il y a de fortes chances que le modèle soit correct — il ne peut simplement pas voir ce dont il a besoin.
Pour en savoir plus sur notre configuration LLM en production, consultez nos benchmarks de modèles et notre traitement de documents basé sur la vision.