Trouver le juste équilibre : Rentabilité des LLM en production
Combien pouvez-vous économiser sans compromettre la fiabilité ?

Feb 5, 2026
En bref Chez ReflektLab, nous équilibrons constamment performance et économie. Notre dernier benchmark a évalué 9 LLM à travers 1 260 tests, mesurant non seulement la précision, mais aussi le coût par point de précision, l'efficacité des tokens, la qualité JSON et la fiabilité en production sur 10 exécutions par test. Au lieu de demander "quel modèle est le meilleur ?", nous avons demandé : combien pouvons-nous économiser sans compromettre la fiabilité ?
Ce que nous avons évalué
Niveau premium : Claude Opus 4.5 (modèle de pointe, référence à coût élevé - exclu du quadrant d'efficacité en raison d'un coût beaucoup plus élevé)
Grands modèles ouverts : Meta Llama 3.3 70B Instruct, DeepSeek V3.2
Milieu de gamme et compressés : GPT-4o-mini, Qwen3 14B, MiniMax M2.1, GLM-4.7 Flash, NVIDIA Nemotron Nano 9B
Petits/compressés : Google Gemma 3N E4B IT (4B paramètres)
Les tâches se sont concentrées sur les charges de travail critiques en production : extraction de produits, génération de schémas JSON complexes et analyse de données structurées. Chaque test a été exécuté 10 fois pour mesurer la fiabilité en production, pas seulement les moyennes.
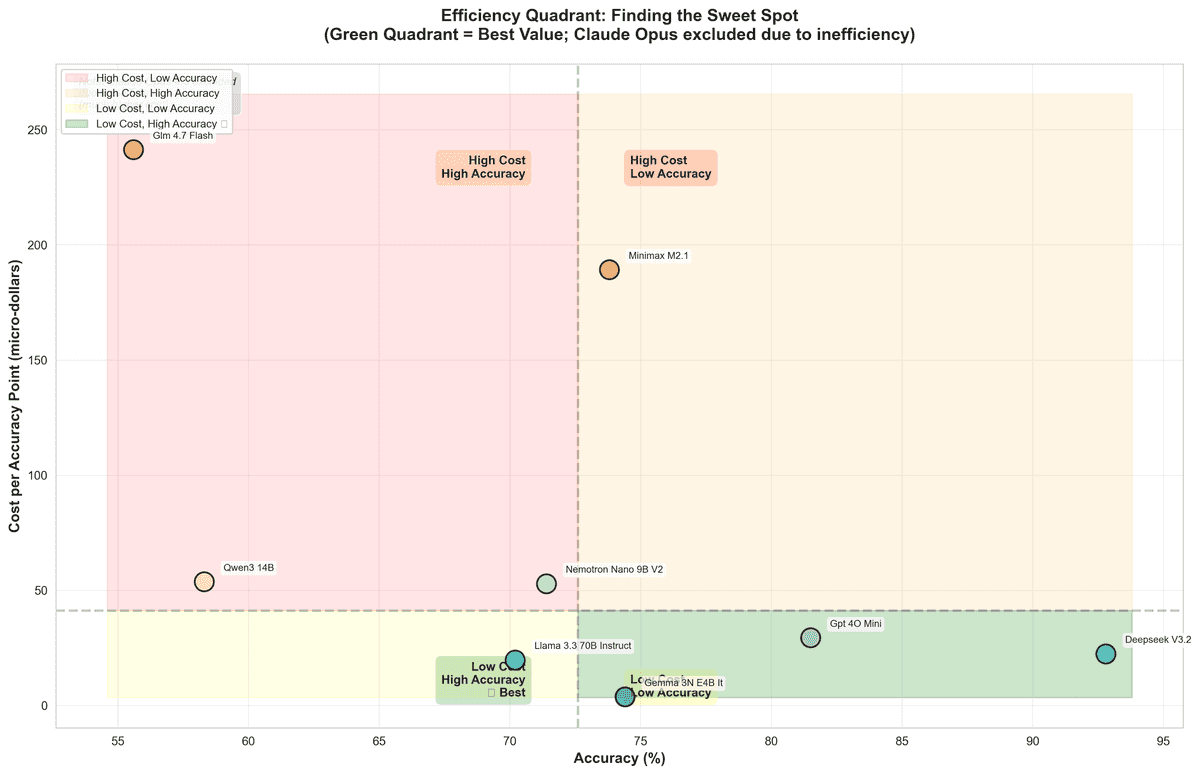
Le paysage de la rentabilité
Plage de précision : Les modèles vont de 55,6% à 92,8% de précision, avec DeepSeek V3.2 en tête à 92,8% — mais ce n'est qu'une partie de l'histoire.
Le coût par point de précision raconte une histoire différente : Google Gemma 3N (4B) atteint 74,4% de précision à seulement 0,00000370$ par point de précision — 390x moins cher que Claude Opus 4.5, qui coûte 0,00144456$ par point de précision malgré seulement 83,3% de précision.
DeepSeek V3.2 émerge comme le champion de l'efficacité : 92,8% de précision (le plus élevé de notre test) à 0,00002240$ par point de précision — offrant des performances de niveau premium à des coûts de milieu de gamme.
L'efficacité des tokens révèle une autre dimension : DeepSeek V3.2 n'utilise que 74,8 tokens par point de précision, comparé aux 662,4 tokens par point de précision de GLM-4.7 Flash — près de 9x plus verbeux pour une précision inférieure (55,6%).
Méthodologie : Coût par point de précision = coût_total ÷ pourcentage_précision, où la précision est calculée comme (tests_réussis ÷ tests_totaux) × 100. Par exemple, un modèle avec un coût total de 0,002$ et 74,4% de précision donne 0,002$ ÷ 74,4 = 0,00002688$ par point de précision. Tokens par point de précision = tokens_totaux ÷ pourcentage_précision, où tokens_totaux inclut à la fois les tokens d'entrée (prompt) et de sortie (complétion).
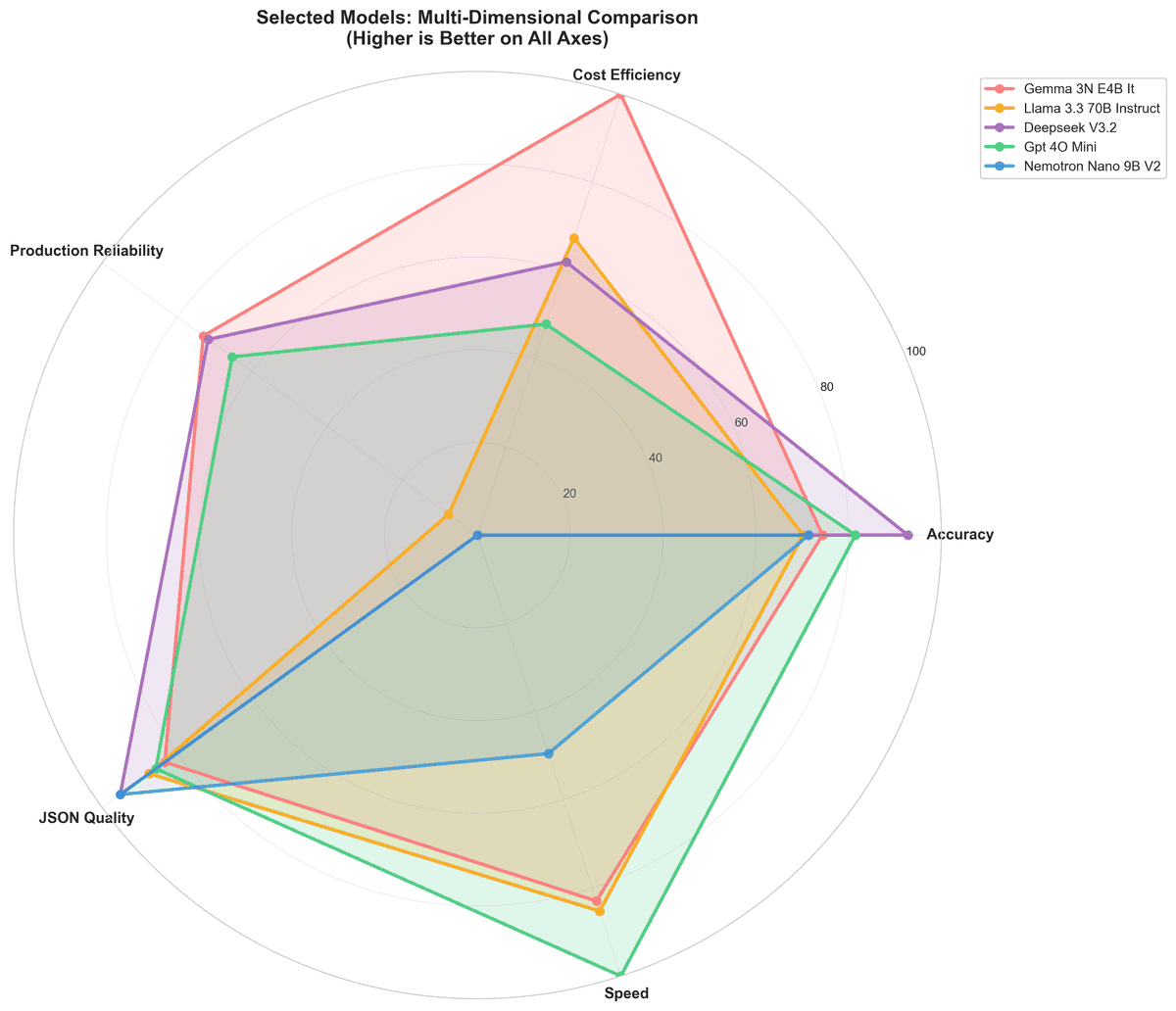
Insights clés
Fiabilité en production : Le coût caché de la variance
Nous avons mesuré le coefficient de variation (CV) sur 10 exécutions. Une variance plus faible signifie des coûts prévisibles et moins de surprises en production.
Les plus fiables : Google Gemma 3N (2,1% CV), DeepSeek V3.2 (2,2% CV), GPT-4o-mini (2,7% CV). Ces modèles délivrent des résultats cohérents d'une exécution à l'autre, critiques pour les systèmes de production où la prévisibilité des coûts compte autant que le coût moyen.
Les modèles à haute variance comme GLM-4.7 Flash (16,4% CV, variations de précision de 45,8%–72,7%) et Qwen3 14B (14,1% CV, variations de précision de 45,8%–66,7%) montrent de larges plages de précision entre les exécutions. Cette imprévisibilité peut entraîner des coûts inattendus et des problèmes de fiabilité en production.
Qualité JSON : Au-delà de la précision
La génération de JSON valide est importante pour les APIs de production. Qwen3 14B atteint 100% de JSON syntaxiquement valide (analysable) avec 99,9% de conformité au schéma (correspondant à la structure requise) — le seul modèle à atteindre une analysabilité JSON parfaite. DeepSeek V3.2 suit avec 95,2% de JSON valide et 95,1% de conformité au schéma.
Plusieurs modèles peinent avec les structures JSON complexes : Gemma 3N, Claude Opus et MiniMax tournent tous autour de 83% de JSON valide, ce qui pourrait nécessiter des couches de validation supplémentaires en production.
Coût vs. Performance : Les niveaux
Niveau budget (moins de 0,00002$ par point de précision) :
- Google Gemma 3N : 74,4% de précision, 0,00000370$/point
- Meta Llama 3.3 70B : 70,2% de précision, 0,00001974$/point
Niveau valeur (0,00002$–0,0001$ par point de précision) :
- DeepSeek V3.2 : 92,8% de précision, 0,00002240$/point ⭐ Meilleur équilibre
- GPT-4o-mini : 81,5% de précision, 0,00002935$/point
- NVIDIA Nemotron : 71,4% de précision, 0,00005289$/point
Niveau premium (plus de 0,0001$ par point de précision) :
- Claude Opus 4.5 : 83,3% de précision, 0,00144456$/point (390x plus cher que Gemma)
Note sur Claude Opus : Notre notation binaire réussite/échec peut ne pas capturer pleinement les capacités nuancées de Claude. Il produit parfois des interprétations alternatives valides que nos tests ont marquées comme incorrectes, sous-estimant potentiellement sa véritable précision. Ses performances réelles sur des tâches de raisonnement complexes peuvent dépasser les 83,3% affichés ici.
Latence : Vitesse vs. Coût
Modèles les plus rapides : GPT-4o-mini (2,147s), Meta Llama 3.3 70B (3,381s), Google Gemma 3N (3,573s). Les plus lents : Qwen3 14B (14,431s), GLM-4.7 Flash (14,368s).
Le compromis : DeepSeek V3.2 est plus lent mais offre la meilleure précision à un coût raisonnable. GPT-4o-mini est le plus rapide avec une bonne précision, ce qui le rend idéal pour les charges de travail sensibles à la latence. Gemma 3N offre le meilleur rapport coût/vitesse pour les cas d'utilisation à haut volume et tolérance de précision plus faible.
Du benchmark à la stratégie de production
Ce benchmark révèle une stratégie de routage par niveaux claire :
Chemin par défaut : Utilisez DeepSeek V3.2 pour les besoins de haute précision (0,00002240$/point) ou Gemma 3N pour les charges de travail à haut volume sensibles au coût (0,00000370$/point).
Chemin critique en latence : Routez vers GPT-4o-mini (moyenne de 2,147s) quand la vitesse compte plus que la précision absolue.
Chemin critique JSON : Qwen3 14B atteint 100% de JSON valide mais montre une haute variance (14,1% CV) avec des variations de précision de 45,8%–66,7% entre les exécutions, le rendant inadapté aux charges de travail critiques. À utiliser uniquement pour des scénarios non critiques avec des protections strictes : validation JSON non critique, traitement par lots avec logique de réessai, ou comme validateur secondaire.
Conclusion
Vous n'avez pas besoin de payer des prix premium pour la plupart des charges de travail en production. DeepSeek V3.2 offre 92,8% de précision à 1/65ème du coût de Claude Opus 4.5. Google Gemma 3N (4B paramètres) atteint 74,4% de précision à 1/390ème du coût — prouvant que les modèles plus petits peuvent gérer efficacement de nombreuses tâches de production.
La clé est de mesurer la fiabilité en production, pas seulement les moyennes. Les modèles avec une faible variance (CV < 5%) offrent des coûts et une fiabilité prévisibles, tandis que les modèles à haute variance introduisent des risques opérationnels cachés.
Si vous optimisez les coûts LLM sans sacrifier la qualité, ces résultats montrent qu'une approche de routage par niveaux basée sur les données peut réduire les coûts de 10 à 100x tout en maintenant une fiabilité de niveau production. La question n'est pas de savoir si vous pouvez vous permettre des modèles premium — c'est de savoir si vous pouvez vous permettre de ne pas mesurer ce dont vous avez réellement besoin.