LLM plus petits, mêmes résultats. Jusqu'où peut-on compresser sans perdre en qualité ?
Puissance maximale, empreinte minimale. Comment les LLM légers atteignent la précision optimale

Jan 28, 2026

En bref Les LLM plus petits et compressés peuvent atteindre des performances proches des modèles de pointe sur de nombreux workloads réels. En mesurant la stabilité, la latence et les performances spécifiques aux langues, il est possible de confier la majorité des tâches à des modèles légers, de réserver les gros modèles pour les cas complexes, et de réduire significativement les coûts sans sacrifier la qualité.
Déployer des LLM plus légers sans sacrifier la qualité
Chez ReflektLab, nous privilégions ce qui fonctionne réellement en production plutôt que le battage médiatique autour des modèles.
Notre dernier benchmark interne compare 13 LLM sur 470 tests, 4 langues (EN/FR/AR/RU) et plusieurs workloads réels : extraction, appariement, classification de messages, vérification de la qualité des données.
Plutôt que de simplement demander « quel modèle est le meilleur ? », nous avons cherché à comprendre jusqu’où nous pouvions pousser la compression et les architectures plus petites sans compromettre les résultats.
Les modèles benchmarkés
Modèles de pointe / grande échelle
- Meta Llama 3.3 70B Instruct (notre modèle par défaut actuel)
- Qwen3 235B
- DeepSeek V3.2
- GLM‑4 32B
- Llama 4 Maverick & Scout
- Gemma 3 27B
Modèles compressés et orientés efficacité
- Distillé : DeepSeek R1 Distill Llama 70B
- Variantes plus petites de Qwen3 : 30B A3B Instruct, 32B
- Optimisé latence : GLM‑4.7 Flash
- Compact Gemma : Gemma 3N E4B
Les tâches reproduisent nos pipelines réels : extraction de produits et quantités, sélection/assise de produits, routage/classification de messages, vérifications ligne par ligne des données.
Chaque test a été exécuté 10 fois par modèle pour mesurer à la fois la performance moyenne et la stabilité (écart type, distributions par exécution), en termes de précision et de latence.
Compression vs qualité : nos observations
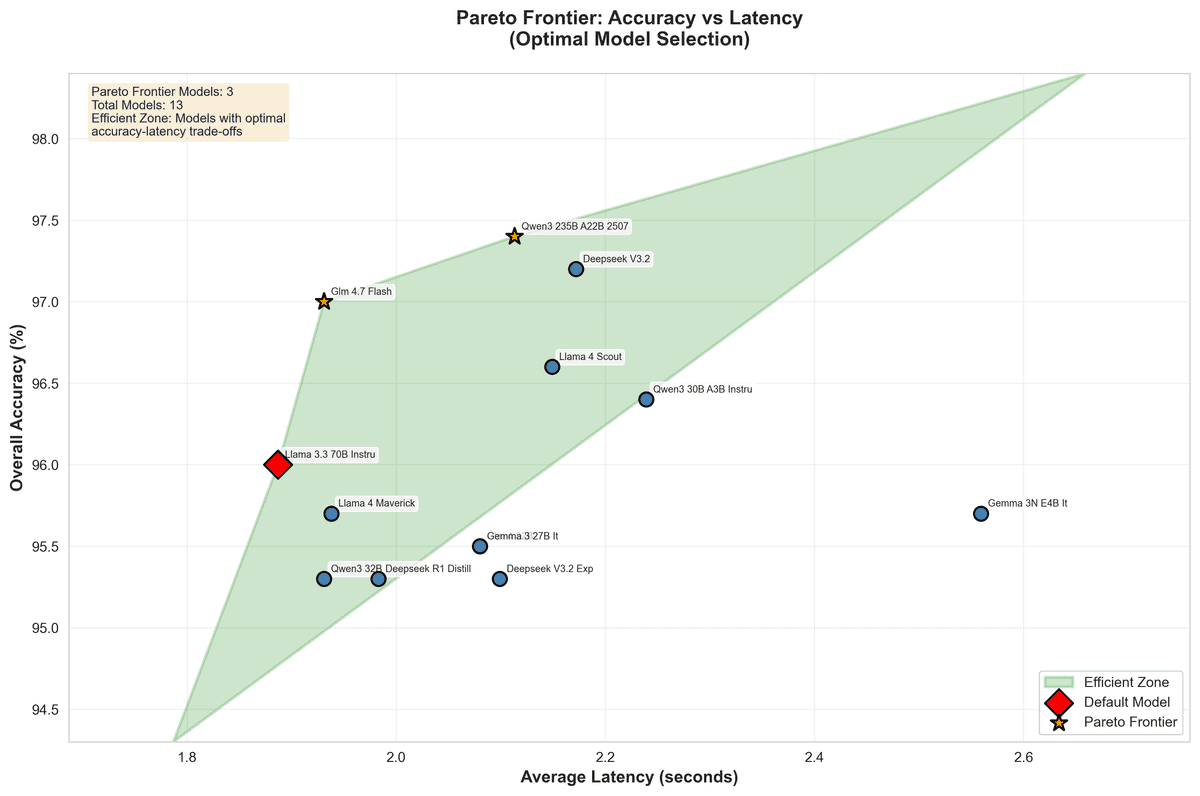
Précision globale La plupart des modèles, y compris compressés, se situent entre 95 et 97 % de précision globale ; le meilleur modèle atteint 97,4 %.
Notre modèle par défaut (Llama 3.3 70B Instruct) atteint 96,0 % de précision et affiche la plus faible latence moyenne (1,887s), ce qui en fait un modèle “ancre” solide pour le routage et les contrôles de régression.
Plusieurs variantes "plus petites" ou distillées (DeepSeek V3.2, GLM‑4.7 Flash, Qwen3 30B/32B, Gemma 3N) égalent ou surpassent les grands modèles sur certaines tâches et langues, souvent avec une latence plus faible et une stabilité très similaire.
Pour des tâches limitées comme l’extraction de produits, de nombreux modèles — y compris compressés — atteignent 100 % de précision, les rendant idéaux pour les workflows sensibles aux coûts.
En résumé : pour une grande partie de nos workloads, il est possible de détourner certaines tâches des gros modèles tout en restant proche de la précision maximale, et en réduisant latence et coût.
Points clés
Stabilité : la fiabilité en production prime
Chaque test a été répété 10 fois pour mesurer la variance, pas seulement la moyenne. Notre modèle par défaut (Llama 3.3 70B) présente une variance de précision de 1,21 %, plus stable que le meilleur modèle (3,30 %). En production, cette différence se traduit par des performances prévisibles vs des échecs imprévisibles.
Plusieurs modèles compressés égalent ou surpassent les grands modèles en stabilité, ce qui les rend adaptés aux workloads à fort volume.
Insights par langue
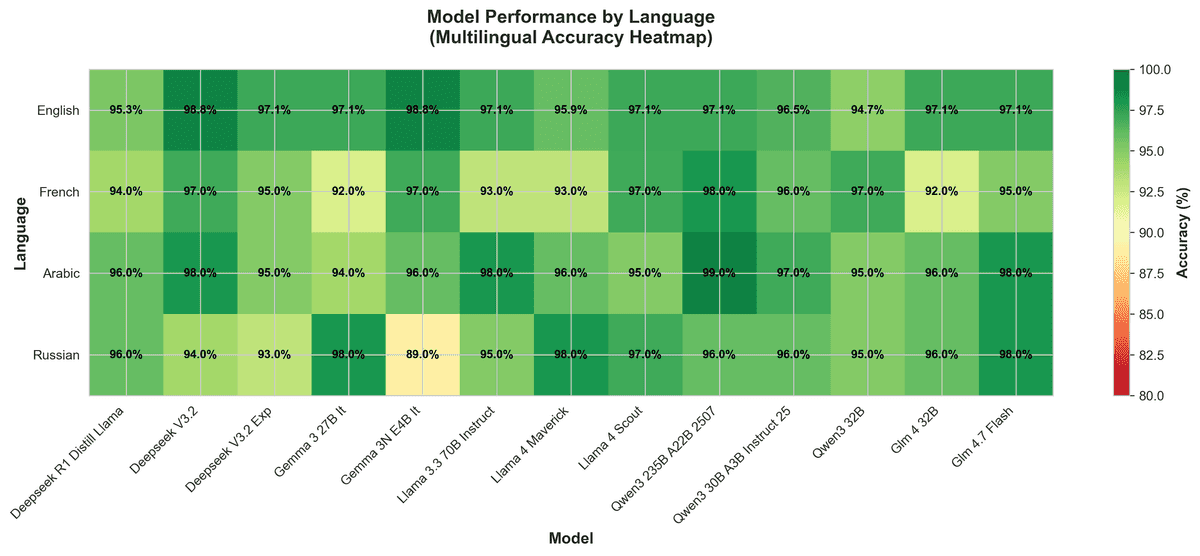
Les performances multilingues varient fortement :
- Arabe : Qwen3 235B atteint 99 % de précision
- Russe : GLM‑4.7 Flash (modèle compressé) atteint 98 % — surpassant les grands modèles
- Français : notre modèle par défaut est le plus rapide, mais Qwen3 235B est le plus précis
Cette matrice langue-tâche guide nos décisions de routage : chaque modèle excelle selon les combinaisons.
Compromis coût/latence
La latence varie de 1,887s (le plus rapide) à 2,559s (le plus lent) — soit une différence de 35 % qui se cumule à grande échelle.
Pour la classification de messages, Gemma 3N E4B (4B paramètres) est 20 % plus rapide que notre 70B par défaut tout en maintenant 100 % de précision.
Ces compromis impactent directement les coûts d’infrastructure et l’expérience utilisateur, faisant du choix du modèle une décision stratégique.
Du benchmark au blueprint
Ce benchmark n’est pas un simple diaporama ponctuel, mais un plan pour concevoir une stack LLM adaptée aux contraintes réelles.
Une stratégie de routage par niveaux émerge naturellement : utiliser des modèles compressés par défaut selon la tâche et la langue, et garder quelques modèles de pointe solides comme fallback pour les cas à forte incertitude ou à risque élevé.
Les swaps de modèles et les choix de compression sont guidés par une évaluation continue, avec la variance par exécution et la stabilité considérées comme des métriques de première classe, plutôt que de ne regarder que les "meilleurs chiffres".
Si vous souhaitez combiner compression, routage et évaluation pour livrer plus rapidement sans exploser votre budget GPU, ces résultats montrent qu’une approche pragmatique et basée sur les mesures permet d’atteindre une qualité proche de l’état de l’art avec une infrastructure beaucoup plus légère.