Transcrire des messages vocaux mixtes arabe-anglais : ce que nous avons appris des vraies commandes d'épicerie aux EAU
Nous avons testé Whisper, des modèles fine-tunés, ElevenLabs et Hamsa sur 25 vrais messages vocaux WhatsApp — aucun n'a atteint une précision de production.

Feb 19, 2026
En résumé : Nous avons testé OpenAI Whisper, un modèle fine-tuné Hugging Face, ElevenLabs et Hamsa sur 25 messages vocaux WhatsApp réels provenant d'épiceries aux EAU — des messages où les locuteurs alternent librement entre l'arabe du Golfe et l'anglais, souvent avec un accent indien. Aucune solution prête à l'emploi n'a atteint une précision suffisante pour la production. Voici tout ce que nous avons trouvé, ce qui a amélioré les résultats, et ce qui n'a pas fonctionné.
Pourquoi l'audio multilingue reste un problème non résolu
Si vous avez déjà essayé de faire du speech-to-text sur un message vocal WhatsApp de Dubaï, vous connaissez le problème. Un seul message de 15 secondes peut contenir une salutation en arabe, un nom de produit en anglais, un prix en chiffres arabes et un nom de marque prononcé avec un accent indien — le tout en même temps.
Ce phénomène s'appelle le code-switching : les locuteurs alternent fluidement entre deux langues ou plus au sein d'un même énoncé. Aux EAU, c'est la norme, pas l'exception. Des millions de messages vocaux quotidiens sur WhatsApp mélangent l'arabe du Golfe avec l'anglais (et parfois l'hindi ou l'ourdou), en particulier dans le commerce — commandes d'épicerie, fournitures de restaurant, instructions de livraison.
La plupart des API de speech-to-text ont été conçues pour l'audio monolingue. Elles supposent une seule langue par énoncé, et elles échouent — ou échouent silencieusement — quand cette hypothèse ne tient plus.
Nous avons voulu mesurer exactement à quel point, et ce qu'on peut y faire.
Notre protocole de test
Les données
- 25 vrais messages vocaux WhatsApp provenant de commandes d'épicerie aux EAU
- Format audio : OGG/Opus (natif WhatsApp), converti en WAV 16kHz mono
- Langues : Arabe du Golfe avec mots et phrases en anglais intégrés
- Locuteurs : Multiples, dont des locuteurs avec accent indien
- Contenu : Commandes de produits ("two boxes of Davidoff Gold"), planification ("come at 7 o'clock"), prix ("170 dirhams") et conversation générale
Méthodologie d'évaluation
Chaque échantillon a été examiné indépendamment par rapport à sa transcription de référence par un seul évaluateur et classé dans l'une des trois catégories :
- Précis — La transcription capture correctement toutes les informations clés (produits, quantités, prix, noms). Les variations mineures d'orthographe ou les mots de remplissage sont acceptables. Correspond approximativement à un WER < 20%.
- Partiellement correct — Certaines informations clés sont correctes mais au moins un élément significatif est erroné ou manquant. Correspond approximativement à un WER de 20-50%.
- Erreurs majeures — La transcription est fondamentalement fausse : mauvaise langue détectée, mauvais produits, contenu halluciné ou sortie complètement inintelligible. Correspond approximativement à un WER > 50%.
Limitation : Les classifications ont été effectuées par un seul évaluateur, ce qui peut introduire un biais subjectif, en particulier pour les cas limites Précis/Partiel.
Ce que nous avons testé
| Approche | Description |
|---|---|
| OpenAI Whisper large-v3 | Baseline, le modèle STT open-source le plus utilisé |
| Whisper + normalisation du volume | Prétraitement audio avec ffmpeg loudnorm avant transcription |
| Whisper + multi-tentatives | 3 passes de transcription avec différentes configs, sélection de la meilleure |
| Whisper + découpage audio | Division de l'audio en segments de 5 secondes avec 1 seconde de chevauchement |
| Modèle HF fine-tuné | Arabic-Whisper-CodeSwitching-Edition, fine-tuné sur des données de code-switching arabe-anglais |
| Post-traitement LLM | Envoi de la sortie Whisper à travers un LLM pour correction et nettoyage avec contexte du catalogue produit |
| ElevenLabs | API commerciale de speech-to-text (5 échantillons uniquement) |
| Hamsa | ASR open-source axé sur l'arabe par NADSOFT |
Les résultats : Whisper Baseline
Sur 25 échantillons avec Whisper large-v3 standard :
| Catégorie | Nombre | Pourcentage |
|---|---|---|
| Transcription précise | 6 | 24% |
| Partiellement correct | 8 | 32% |
| Erreurs majeures | 11 | 44% |
Seulement 24% des messages vocaux ont été transcrits avec une précision suffisante pour être utilisables. Près de la moitié avaient des erreurs critiques — mauvais produits, mauvais chiffres, ou contenu entièrement halluciné.
Le tableau s'aggrave — et ne s'améliore pas — quand on applique les stratégies d'amélioration courantes :
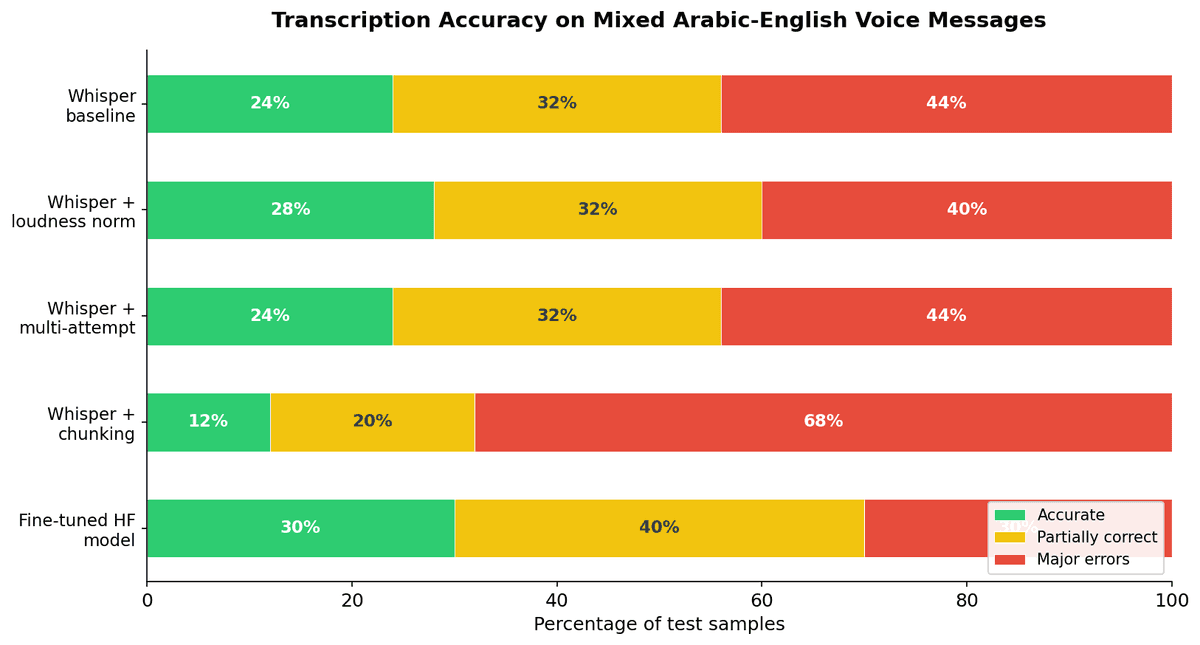
Le découpage (division de l'audio en segments de 5 secondes) a en fait significativement dégradé la qualité, faisant chuter la précision à seulement 12%. Le modèle fine-tuné Hugging Face a montré le plus de promesses à 30% de précision, mais reste loin d'être prêt pour la production.
Les modes d'échec
1. Mauvaise détection de langue
Whisper a fréquemment mal identifié la langue. De l'audio arabe a été transcrit en lituanien, indonésien, et même en pendjabi. Quand le modèle choisit la mauvaise langue, chaque mot de la sortie est faux.
2. Confusion des chiffres et unités
Les prix et quantités ont été systématiquement déformés — un échec critique pour le commerce. "170 dirhams" est devenu "160 degrés." "Kilo d'oignons" est devenu "kilo de moules."
3. Hallucination et répétition
Whisper a parfois halluciné des noms de produits entiers qui n'ont jamais été prononcés. L'expression "Lucien cake" est apparue dans 5 échantillons où elle n'a jamais été mentionnée — un biais connu des données d'entraînement.
4. Échec du code-switching
Quand un locuteur disait "two boxes of Davidoff Gold" au milieu d'une phrase en arabe, Whisper traduisait soit tout en anglais (perdant le contexte arabe), gardait tout en arabe (déformant les noms de marque anglais), ou mélangeait incorrectement les scripts.
Ce que nous avons essayé pour corriger
Normalisation du volume — Gain à faible risque
La normalisation du volume audio avec ffmpeg avant la transcription a apporté une amélioration marginale mais constante. C'est essentiellement gratuit — pas de perte de précision, une sortie légèrement plus propre sur les enregistrements silencieux.
Verdict : À conserver. Petit gain, zéro risque.
Transcription multi-tentatives — Pas d'amélioration mesurable
Exécuter 3 configurations de transcription différentes par fichier audio et sélectionner le meilleur résultat semble prometteur. En pratique, toutes les méthodes ont échoué sur les mêmes échantillons et réussi sur les mêmes échantillons.
Verdict : Ne vaut pas la latence et le coût supplémentaires.
Découpage audio (segments de 5 secondes) — A empiré les choses
Diviser l'audio en courts segments avec chevauchement a en fait dégradé la qualité. Les segments courts ont perdu le contexte et produit des artefacts.
Verdict : Ne pas utiliser le découpage pour les messages vocaux courts.
Modèle fine-tuné Arabic Code-Switching (Hugging Face)
Nous avons testé Arabic-Whisper-CodeSwitching-Edition, un modèle spécifiquement fine-tuné pour l'arabe avec code-switching anglais. Résultats mitigés :
Ses points forts : Il a mieux géré le code-switching que Whisper de base, transcrivant les noms de produits anglais en ligne avec l'arabe — plus proche de la façon dont le locuteur parlait réellement.
Ses faiblesses : Le traitement était ~8x plus lent (42 secondes vs ~5 secondes par échantillon). Il avait toujours du mal avec l'audio peu clair, l'arabe accentué indien et la reconnaissance des nombres.
Verdict : Meilleur pour la préservation du code-switching, mais trop lent et encore peu fiable sur les échantillons difficiles.
Post-traitement LLM — Efficace uniquement quand Whisper s'en sort presque
Nous avons envoyé toutes les tentatives de transcription à travers un LLM (avec un contexte de catalogue produit de 11 844 articles) pour corriger, traduire et nettoyer la sortie. Le LLM :
- A corrigé "degrés" en "dirhams" (connaissance du domaine)
- A supprimé les phrases dupliquées et les répétitions
- A traduit l'arabe en anglais propre
- A standardisé les noms de marque en utilisant le catalogue produit
Mais il ne peut pas corriger ce que Whisper a fondamentalement mal compris.
| Qualité de la transcription de base | Efficacité du LLM |
|---|---|
| Bonne (24% des échantillons) | Excellente — sortie propre, traduction correcte |
| Partielle (32% des échantillons) | Modérée — corrige les problèmes mineurs, manque les majeurs |
| Mauvaise (44% des échantillons) | Minimale — ne peut pas récupérer un contenu erroné |
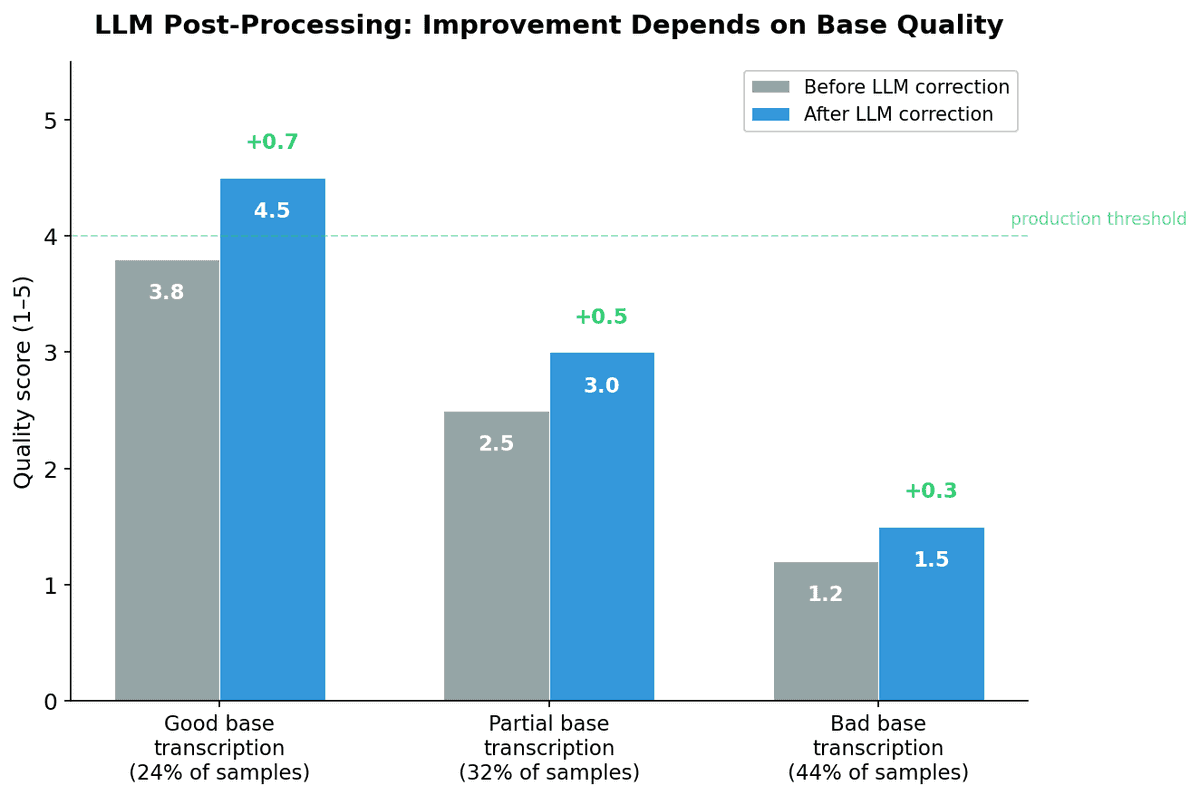
Verdict : Utile comme couche de nettoyage, mais pas un substitut à une transcription de base précise.
Alternatives commerciales et open-source
Nous avons également testé ElevenLabs (5 échantillons) et Hamsa (ASR open-source axé sur l'arabe). Aucun n'a significativement surpassé Whisper sur nos échantillons multilingues avec accent indien.
L'insight code-switching : indiquer la langue non-anglaise
Une découverte s'est démarquée. Nous avons effectué un test contrôlé avec de l'audio mixte russe-anglais et trouvé un insight de configuration critique :
| Configuration | Code-switching préservé | Qualité |
|---|---|---|
| Auto-détection | Non (traduit tout en anglais) | Bonne |
| Indice anglais (-l en) | Non (traduit tout en anglais) | Bonne |
| Indice non-anglais (-l ru) | Oui | Meilleure |
| Prompt multilingue | Partiel | Faible |
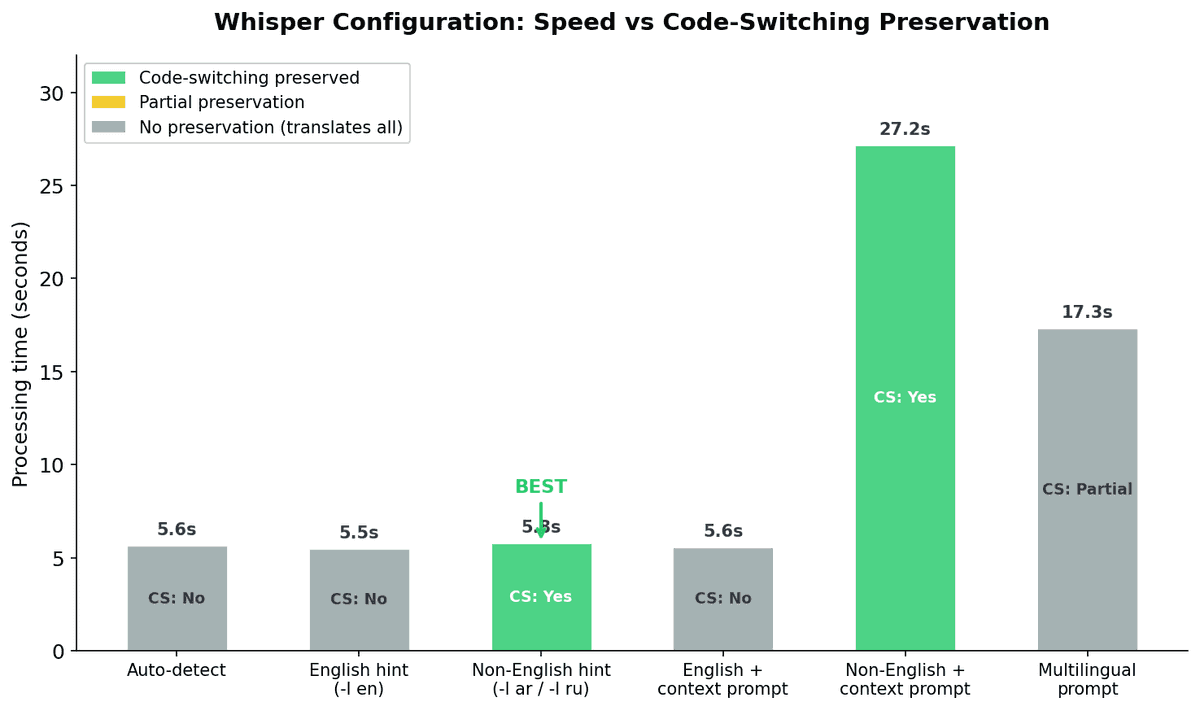
Quand on dit à Whisper d'attendre la langue non-anglaise, il préserve le code-switching — à la même vitesse que toute autre configuration (~5,8 secondes).
Cela s'applique aussi à l'arabe-anglais : utiliser -l ar préserve mieux le code-switching naturel que l'auto-détection.
Points clés pour construire du STT multilingue
1. Les modèles prêts à l'emploi ne résolvent pas le code-switching en qualité production
24% de précision n'est pas prêt pour la production. Si vous construisez des workflows vocaux pour des marchés multilingues comme les EAU, prévoyez un effort d'ingénierie significatif au-delà de "il suffit d'utiliser Whisper".
2. Le goulot d'étranglement est la transcription de base, pas le post-traitement
Aucune quantité de correction LLM, d'ingénierie de prompts ou de stratégies multi-tentatives ne peut corriger des transcriptions fondamentalement fausses.
3. Le prétraitement audio aide mais ne change pas la donne significativement
La normalisation du volume vaut la peine d'être activée. Le découpage non. La transcription multi-tentatives montre des rendements décroissants.
4. Les indices de langue comptent plus qu'on ne le pense
Pour l'audio avec code-switching, indiquez toujours la langue non-anglaise. Ce seul changement de configuration peut faire la différence entre perdre toute la structure bilingue et la préserver.
5. L'arabe avec accent indien est particulièrement difficile
Une part significative des communications vocales dans le commerce aux EAU provient de locuteurs sud-asiatiques utilisant l'arabe du Golfe. Cette combinaison accent/dialecte semble sous-représentée dans les données d'entraînement de la plupart des modèles ASR.
6. Le contexte de domaine est précieux — quand la transcription de base est proche
Les catalogues produits, les listes de noms de marque et les dictionnaires de patterns d'erreur aident réellement une couche de post-traitement LLM. Mais ils ne fonctionnent que quand la transcription brute est dans le bon ordre de grandeur.
Et après ?
Nous travaillons activement sur :
- Le fine-tuning sur des données spécifiques aux EAU — arabe du Golfe, arabe accentué indien, vocabulaire du domaine alimentaire
- Des architectures de pipeline hybrides — combinant la vitesse de Whisper avec la précision de modèles spécialisés
- Le routage basé sur la confiance — utilisant les scores de confiance de transcription pour décider quand une revue humaine est nécessaire vs quand le traitement automatisé est sûr
- Un benchmarking élargi — testant plus d'API commerciales et de modèles open-source car l'espace évolue rapidement
La transcription vocale multilingue sur des marchés comme les EAU est un problème difficile — mais c'est aussi une opportunité massive. La première équipe à le résoudre de manière fiable débloquera le commerce vocal pour des millions d'utilisateurs.
Chez ReflektLab, nous construisons des outils alimentés par l'IA pour le commerce sur les marchés multilingues. Si vous travaillez sur des défis similaires avec la reconnaissance vocale arabe, la transcription multilingue ou les systèmes de commande vocale, nous serions ravis d'échanger.